
The interesting part of this project is not that a curve goes up. It's that measurement contradicted the pitch — and the repo reports the contradiction. The cascade's end-to-end F1 climbs from 0.340 at Tier 1 to 0.794 once Tier 2 is added, then drops to 0.768 when the quantized 32B Tier 3 joins. That regression ships as-is, documented and explained, rather than smoothed into a nicer-looking story.
The system itself is straightforward to state: healthcare patient intake (CMS-1500) and business documents (invoices, POs) arrive as PDFs or page images, and validated, typed JSON comes out. What makes it worth reading is everything around that — the cost-routing cascade, the human-in-the-loop review queue that's populated by design, the integrity guardrails that keep the headline chart honest, and the consumer-hardware reality that forced a measured trade-off instead of an aspirational one.
01 // What It Is
A self-improving intake-form extraction pipeline. A three-tier extraction cascade routes each field to the cheapest model that can handle it confidently and escalates only when confidence is low. Reviewer corrections feed back into an alias table and a ColQwen 2.5 retrieval corpus, so later extractions on similar documents resolve at Tier 1 more often.
V1 runs the entire cascade locally on two GPUs — an RTX 4080 plus an RTX 4060 Ti, 32 GB combined — with no cloud, no deployed URL, and $0/1K inference. That is the complete deliverable, not a prototype waiting on a hosting bill. The optional V2 enhancement exists for exactly one reason: processing real PHI requires BAA-eligible providers, so V2 would swap the middle and top tiers for BAA-cloud services (Textract Queries, Bedrock) behind the same provider Protocol, wire the local tiers to a deployed endpoint, and stand up a public demo. The in-tree Terraform (infra/terraform/) and the architecture docs describe that target so it reads as a credible, scoped enhancement rather than hand-waving — but it is not built and not scheduled.
02 // The Headline Result
The chart above is the project's headline, measured on a held-out test split and reproduced from the same cached run. The numbers:
| Cascade stage | End-to-end F1 | What the tier adds |
|---|---|---|
| Tier 1 — PaddleOCR-VL | 0.340 | layout parse + alias-table match |
| + Tier 2 — Qwen 2.5 VL 7B | 0.794 | the real lift |
| + Tier 3 — Qwen 2.5 VL 32B · Q4_K_M | 0.768 | −0.026 — regresses |
test partition of a 584-document local corpus (500 Synthea patients → CMS-1500, rendered 1:1; train 394 / dev 98 / test 92, zero patient leakage). Both panels of the chart are the same cascade run.
The cascade is not monotone. The Qwen 7B Tier 2 does the real lift; adding the Q4_K_M-quantized 32B Tier 3 regresses −0.026. Tier 3 only ever re-extracts the fields that escalated (confidence < 0.80), and the locked 0.5-confidence heuristic on coerced scalars forces every date field below that gate even when Tier 2 had it right — so the quantized 32B re-extracts those dates and overwrites correct values (29 of 31 changed fields go correct → wrong, nearly all dates). It ships as-is rather than engineered monotone; a better (unquantized, reasoning) local Tier-3b is the measured lever to fix it, not a framing change. What does rise monotonically is the escalation funnel — cumulative cells resolved climbs to 100% of the 981 populated cells, because Tier 3 still finalizes the residual the earlier tiers couldn't clear.
03 // How It Works
A two-stage router classifies the vertical: a deterministic local vocabulary match handles ~80% of documents with no network hop, and only the ambiguous remainder hits an LLM fallback (local Qwen 7B in V1, Bedrock Nova Lite in V2 — one provider swap, identical routing logic above it). The chosen Pydantic schema seeds the cascade.
An in-process Python orchestrator (no state machine in V1; V2 wraps it in Step Functions) runs the tiers. PaddleOCR-VL is a layout parser whose blocks run through an alias-table-driven layout-to-fields post-processor; fields below the 0.85 threshold escalate to a prompted Qwen 2.5 VL 7B, then to Qwen 2.5 VL 32B below 0.80. Cheap fields settle at Tier 1 in sub-second-per-page; only the fields Tier 1 can't resolve pay GPU time higher up. The assembled form's minimum confidence decides auto-approval versus the human review queue. A reviewer's correction writes back with full provenance, appends any missed label phrasing to a runtime alias overlay, and re-embeds the document into the ColQwen corpus — so the next similar document resolves earlier.
The whole system persists to one SQLite file (extracted fields, eval log, ColQwen multivectors), intentionally Aurora-compatible so the V2 migration is a row-copy rather than a redesign. docs/architecture-deep-dive.md covers the orchestrator, persistence model, and the optional enhancement's cloud edge.
04 // Human In The Loop
The review queue is the cascade's HITL surface — where any populated field still below the 0.80 confidence gate after Tier 3 is parked rather than silently accepted. It is populated by design. The locked 0.5-confidence heuristic scores every coerced scalar (date / int / float / bool) at exactly 0.5 — below the gate — even when the value is extracted correctly, so every form with a date field reaches a human. A non-empty queue is the intended operating point of a cascade built around adjudication, not an error rate to drive to zero; the heuristic and gate are frozen (Phase 5/6) and deliberately not tuned to empty it.
Park ≠ fix. Parking a field for review does not change its F1 contribution: a wrong-but-parked value still counts as a false positive against ground truth. This is the deliberate guard against the obvious gaming path — if "sent to review" excused a field from scoring, the headline could be inflated by parking anything the cascade was unsure of. The queue is operational triage layered on top of the metric, never a metric adjustment.
Corrections submitted from the queue flow back through src/rag/aliases.py: any on-form label phrasing the cascade missed is appended to a runtime overlay (src/data/corrections_aliases.json, gitignored), unioned onto the frozen v1.0.0 seed at load time and taking effect for the next extraction. The committed seed is never mutated — the progressive-alias-partition sweep calls rag.aliases.suppress_overlay() so the published artifact can't silently drift from accumulated live corrections. docs/eval-methodology.md has the full methodology framing.
05 // What's Worth A Closer Look
06 // Running It
git clone https://github.com/marky224/intake-form-ai-pipeline
cd intake-form-ai-pipeline
just install # uv sync + pre-commit
just test # 1077 tests (1058 fast + 19 slow)
just lint # ruff + ruff-format + black
just demo # Streamlit on :8501 — real 3-tier cascade over the
# 92-doc test split via cached replay. $0, no GPU.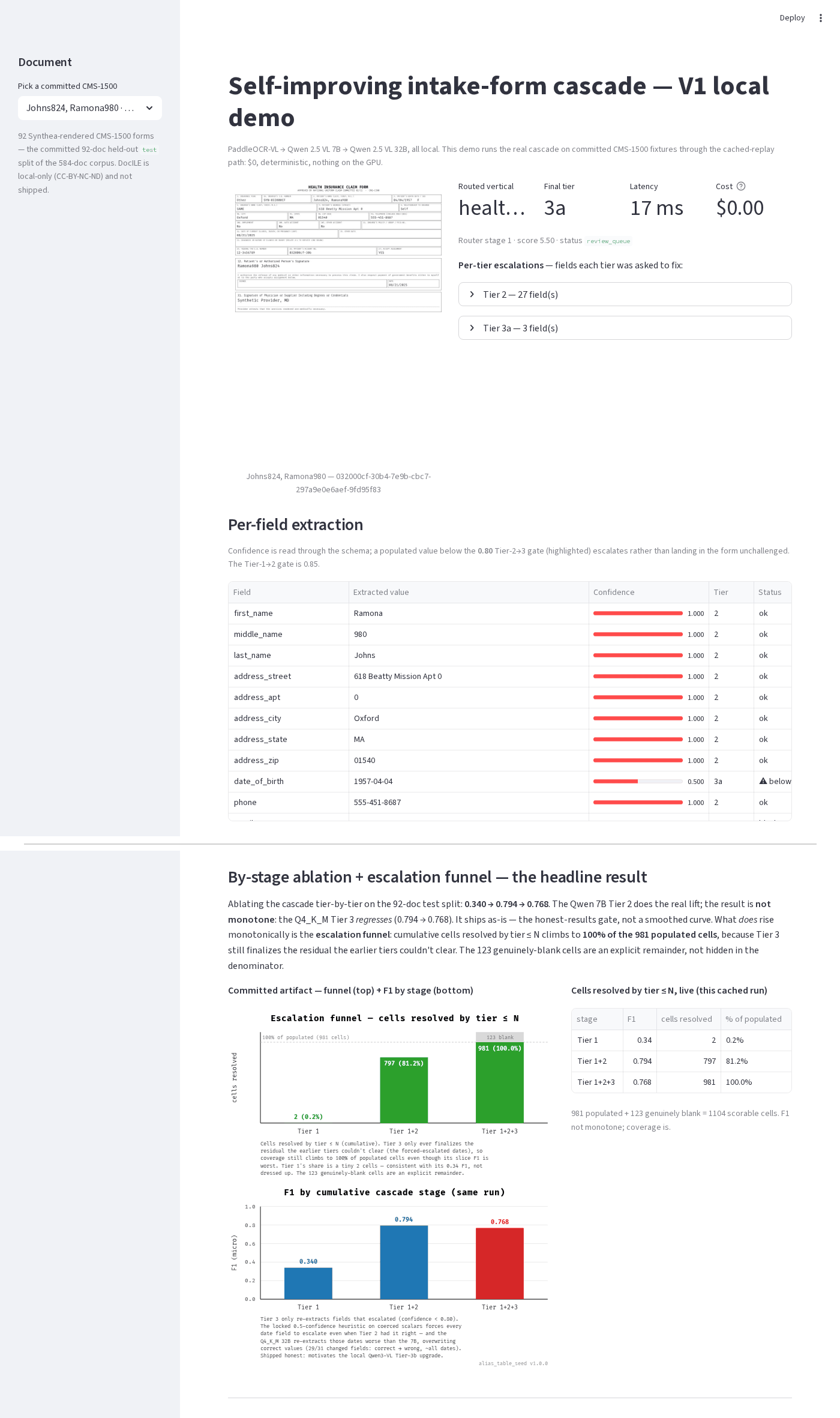
The demo surfaces, per document: the rendered form, routed vertical and final tier, per-tier escalations, the per-field value/confidence/tier table, the populated review queue, and — as the headline analytics — the by-stage ablation + escalation funnel (the honest non-monotone F1 0.340 → 0.794 → 0.768 shown beside the monotone cells-resolved coverage rising to 100%, both from the same cached run). For live on-GPU inference, ollama pull qwen2.5vl:7b qwen2.5vl:32b, install PaddleOCR-VL per docs/local-development.md, then EVAL_LIVE=true just demo. No cloud calls, no AWS credentials, either way. just eval / by-stage run the harness and regenerate the CI-drift-guarded SVG.
07 // Project Structure
intake-form-ai-pipeline/
├── src/ # installable editable package (uv sync)
│ ├── intake_schemas.py # Pydantic v2 schemas (canonical artifact)
│ ├── build_alias_seed.py # regenerates alias_table_seed.json
│ ├── _paths.py # repo_root() / src_root() — single path resolver
│ ├── cascade/ # provider Protocol, tier1/2/3, orchestrator, router, store
│ │ └── providers/ # tier1_paddleocr_local, tier2_qwen_7b_local, tier3_qwen_32b_local
│ ├── evals/ # F1/latency metrics, manifest, progressive alias partition, by-stage chart
│ ├── rag/ # ColQwen 2.5 retrieval + correction feedback loop
│ ├── finetune/ # QLoRA text post-corrector (Phase 9 experiment)
│ ├── demo/ # Streamlit: data.py (testable core) + app.py (view)
│ ├── synthetic_data/ # synthea/, render/ (Playwright CMS-1500), docile/
│ ├── tests/ # 1077 tests + fixtures/ (eval-cache, eval-validation, synthea, docile)
│ └── data/ # SQLite v1.db + ColQwen .npy cache (gitignored runtime)
├── alias_table_seed.json # 465 aliases / 86 records, frozen v1.0.0 (canonical, repo root)
├── scripts/ # dev tooling (regen fixtures, dual-quant sanity)
├── infra/ # terraform/ (optional-enhancement target; bootstrap live) + bicep/ (no-deploy parallel)
└── docs/ # architecture-deep-dive, hipaa-architecture, eval-methodology,
# production-roadmap, local-developmentPython 3.11+, Pydantic v2, uv, pytest, ruff + black, pre-commit from Phase 1. GitHub Actions runs four required checks on every PR — Lint, Test, Secret scan (gitleaks), and IaC scan (checkov against the in-tree Terraform).
08 // Further Reading
docs/architecture-deep-dive.md— the shipped V1 orchestrator + persistence; the optional enhancement's cloud edge, five-tier routing, Step Functions layout, sequence diagrams.docs/eval-methodology.md— F1 computation, partition/leakage discipline, progressive alias partition, the two-stage finding, the by-stage ablation, Phase 8/9 deviations.docs/hipaa-architecture.md— why the optional cloud enhancement exists: the BAA boundary, three-layer enforcement, the real-PHI swap path.docs/production-roadmap.md— the one optional future enhancement (BAA-cloud for real PHI) plus considered-not-done items (Qwen3-VL mixed-precision, Spanish, vLLM scale-up, Bedrock adapter import).docs/local-development.md— GPU/Ollama setup, multi-GPU split, the Tier 3 Q4_K_M trade-off, Synthea + DocILE workflows.RATIONALE.md— schema design rationale (DataClass enum, ExtractedField wrapper, SignatureCapture, BoundingBox, confidence aggregation).
Full source is open at github.com/marky224/intake-form-ai-pipeline — schema layer, cascade, eval harness, Streamlit demo, synthetic-data pipeline, and the in-tree Terraform for the optional BAA-cloud enhancement.